
Data science and analytics are critical components of many industries. However, with the emergence of modern technology in the late 20th century, automated data collection systems have become commonplace throughout the finance industry.
It is clear that to be successful in this field, data must continuously be tracked and reported back accurately. Web scraping in the finance sector also goes hand-in-hand with data science.
When we talk about scraping financial data, various metrics from the most critical finance areas receive priority. These include the stock market, trading prices, securities changing, the future of your mutual fund, cryptocurrencies (such as bitcoin), financial statements, and other types of information that could prove advantageous in this field.
Because this system is crucial to gathering large amounts of information, it is essential to build a data web scraping tool that is reliable and accurate.
This post will discuss the various ways web scraping is advantageous and how to build successful web scraping tools.
What is Web Scraping?
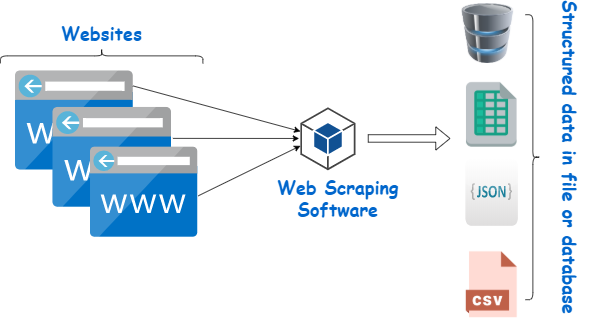
For many, web scraping may be challenging to master, as it can be quite confusing for the novice. Web scraping is one of the most accurate ways to gather large amounts of data and is often built using coding languages, such as web scrapers built-in Python.
In short, the concept of web scraping is simply a means for extracting data from a website. It is popular in the financial sector due to its popularity with Yahoo Finance users.
There are a couple of different ways to scrape data from the web. Some users will prefer to scrape data manually, but automated web scraping tools allow you to retrieve data in real-time. However, building a web scraper can be difficult, as websites vary significantly; therefore, the web scraper must adapt.
How Does a Web Scraper Operate?
A web scraper’s standard functionality is that the tool is given various URLs for the websites you want it to analyze. Then, the tool loads the HTML code and begins gathering data.
Web scrapers can vary in functionality, as more intricate versions can analyze javascript and CSS. After the code loads into the tool, it will begin collecting the data. It could collect data from the entire page or just the data that is the most essential.
Selecting only the data you need is advantageous. For example, suppose you are scraping on Yahoo Finance and want only specific data, such as stock prices. In that case, the tool will gather just that data, making it even easier to collect the most important information.
Why is it Important to Scrape Financial Data?
When it comes to finance and data science, most of the data collected is financial statements and data collected from the stock market. Much of this data is useful for analyzing competitors, ensuring your firm is doing its best to remain competitive in the market.
The world of finance is exceptionally data-heavy and analytical; therefore, reliable data from reputable sources is critical to your institution’s performance. Web scraping has become advantageous for financial data because it can collect data in real-time.
Because web scrapers can be customized only to collect certain types of data, almost any data you need is available. The data most important to financial professionals are financial statements, such as the income statement, balance sheet, and statement of cash flows. These are all essential to gauge a company’s financial health and well-being and give you the information needed to invest properly.
You can also gain real-time updates on customer relationship management data to see what clients are looking for or demanding from a business, potentially improving overall customer satisfaction.
However, because the data is collected quickly and in real-time, it is critical to have a sufficient storage database. It is essential to ensure that your databases are updated continuously and old data removed.
How to Use Scraping Templates
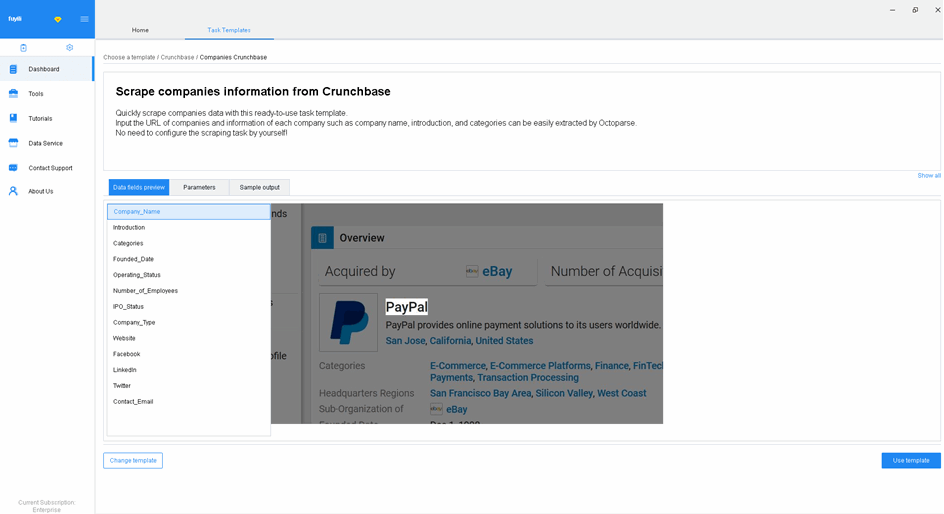
Web scraping templates are one of the many reasons that the use of web scraping is so widespread. They allow you to construct web scraping tools without having to be well-versed in Python.
Web scraping templates are a great way to create an efficient web scraper in little time. These are often easy to use, as the code is already pre-written. Usually, the only aspect of the code that requires manipulation is the URL you would like to analyze.
This is great for those who want to scrape financial data but are not familiar with coding. Python is often used and is pre-coded with these templates. These templates allow anyone in the financial sector to create reliable web scraping tools catered to their needs.
What Coding Language Should You Use?
The world of coding can be daunting for those not well versed in the subject. For web scraping, Python is used, often due to its simple syntax. Python is popular for scraping tools because it is open source and easy to learn.
Its functionality is also an attractive aspect for data science, as it can be easily updated to accommodate real-time data. Python is also highly adaptable, which is critical in all facets of data science.
Python is especially advantageous in the financial sector due to its syntax, which is very easy to read, a critical aspect to mine complex data accurately. The ease of use Python provides makes it an excellent choice for many industries, here are just some of its advantages:
● Simple, easy to read syntax
● Yet able to construct advanced software
● Available support
● Python makes testing codes effortless
● Compatible with other aspects of code
● It can run on almost any operating system, such as Windows, OS, and Linux.
● It’s free
Python has various libraries that are great for scraping financial data; these include:
● Numpy
● Pandas
● Matplotlib
● Scripy
● Scikit-learn
With the ease of use, Python provides and the various libraries available, you can easily create web scraping tools even without coding experience.
How to Build Web Scraping Tools

There are various ways to mine data. You can parse through a single page or scrape thousands of pages at once. However, you must apply different frameworks to gather such large amounts of data. We will look at how to implement both a single-page web scraping tool and one that parses multiple pages at once.
A. How to Build a Finance Web Scraping Tool for a Single Page
Building a web scraping tool may be intimidating for some; however, it is essential to gather this information quickly. Python is the most popular coding language to build this tool, as it is easy to learn and provides you with the most accurate data. Let’s go over how to make a web scraping tool and the various functionalities available.
1. Find a Reliable Website
The first step to creating a web scraping tool is finding a reliable website, such as Yahoo Finance, downloading the HTML, and ensuring it is compatible with Python. You can then analyze the page using HTML, such as LXML, a parser that can save to a JSON file.
The data that you should extract is the previous close, open, bid, ask day’s range, 52-week range, volume, average volume, market cap, beta, PE ratio, EPS. In some cases, earning’s date, dividend, yield, ex-dividend date, and one-year target estimate are also recorded.
2. Install Python 3
To begin scraping, download Python 3 and ensure that you’ve installed the correct version for your specific operating system. A few different files may need to be downloaded, such as PIP files, Python requests, and Python LXML.
The pre-written code can then be downloaded and can run the scraping tool. To run the tool, you must insert the script of the web page you want to scrape, and place a “-h” at the end and assemble the ticker that records the stock value by implementing the line:
“python webpage name.py AAPL”
This line will allow you to create a JSON file and store it in the script folder. You can also download the JSON file and download it to the script. You can then run the scraper tool and collect various types of financial data.
B. How to Build a Scraper for Multiple Pages
It’s somewhat simple to build a web scraper for just one page; however, when scraping multiple pages, it gets more complicated.
If you plan on scraping well over a thousand pages daily, you will need advanced architecture or professional guidance. You will have multiple scrapers that will have to contact each other to assemble large amounts of data successfully.
Let’s check out a few of the most critical components to collect data on a large scale.
1. URL Queue and Data Queue
URL and data queues are critical to transmitting information to each one of your scrapers. Often, 3rd party programs such as Redis or Kafka are the most effective to transmit the data accurately. These large-scale scrapers read and scrape URLs and transmit them between each scraper.
You can also schedule large-scale data captures using scheduling tools to scrape data as often as needed. One of the most popular tools for scheduling scrapers is a program called Scrapy. This works by entering Scrapyd+cron in Python, allowing you to set your scraping schedules.
2. Constructing Databases
Due to the vast amounts of information scraped, you must have a place to secure it. However, unlike information parsed from a single website and stored in a simple excel or Google slide sheet, large-scale scraping requires databases. These databases are on cloud storage services such as Azure SQL and Redis. Another type of database is a relational database, such as NoSQL.
Constructing databases is one of the best ways to store such large amounts of data, and they are often easily accessible. Often, web scrapers use NoSQL databases such as Cassandra.
Prior to storing your data, it is important to run a few tests to ensure the database operates effectively. This data is easily accessible, allowing you to retrieve it from the database and begin implementing it into your data portfolio. Databases require ample maintenance, as you must regularly remove old data to create space for newly collected data.
Although web page scraping is the norm for many industries, especially the financial industry, some site admins will install tools to prevent scrapers from collecting information. These tools often stop the scrapers by banning their IP, and preventing them from crawling the website. However, tweaking your proxy settings can often mitigate this issue.
Data Scraper Maintenance
Like many computer applications, data scrapers often need maintenance to ensure they are operating efficiently. This includes optimizing them for sudden website changes and ensuring they are utilizing the latest framework. Often, it is best to make changes to the scrapers every few months to ensure they are current.
It is important to program the scraper to notify you when something is wrong or updated. This is critical to collecting ample amounts of data and ensuring it is accurate.
Need Help?
If this sounds like a lot of work for you, you can always hire companies like Zenscrape that will take care of all of the work for you so you can focus solely on improving your business.
Zenscrape’s API allows you to filter and customize your query, so you’re extracting only the most efficient data for your business.
Better yet, Zenscrape offers 1000 API requests per month completely free with no strings attached.
Final Thoughts
The days of complex code and vast technical knowledge needed to gather information are no longer relevant. In today’s highly integrated and data-driven world, automated scraping tools are available to almost anyone in any industry.
Data, analytics, and real-time, accurate readings are critical for many aspects of finance. By creating a finance data web scraping tool, you can quickly and accurately collect data to improve your financial performance. With the right code, maintenance, and storage, you can mine data from millions of web pages in minutes.
Whether you are parsing various websites to collect data for your own firm or are the head of a major financial corporation, a finance data web scraping tool should be your main data collection strategy.






